ESEB poster 2025
I chose to focus on the status of the Thymelaeaceae annotations as I’m currently trying to annotate a bunch of Wikstroemia species, and I wanted to get a better idea about the status of the published annotations.
A link to the full poster is available here.
TL;DR
All the Thymelaeaceae annotations I found have some issues with methods or the generated files themselves. The Aquilaria sinensis and A. yunnanensis annotations are based on transcript evidence and seem pretty okay, and can probably be used as-is, after correcting for files being badly formatted. The Stellera chamaejasme annotation is not based on transcript data and has some pretty clear methods issues, and seems to suffer from over-prediction. If using the Stellera annotation you probably want to account for this in some way.
Methods
Identifying annotations
I have attempted to identify the annotations that are out there, but I might very well have missed something. If you know of an annotation that I should be interested in, let me know! :) Apart from the annotations I had stumbled across and the papers they reference, I also looked at Thymelaeaceae genomes in EBI and did some basic Google Scholar searches, including searching within citing papers etc.
Annotations used
The following table provides an overview of the annotations used.
| Species | Annotation version | Publication doi | OrthoFinder | Exons per gene | OMArk | Expression analysis | Annotation GFF file used | Protein fasta file used | Where the data was accessed |
|---|---|---|---|---|---|---|---|---|---|
| Aquilaria sinensis | Ding et al. 2020 | 10.1093/gigascience/giaa013 | Yes | Yes | Yes | Yes | coding_gene.annotation.gff | pep.fasta | https://gigadb.org/dataset/100702 |
| Aquilaria yunnanensis | Li et al. 2024 | 10.1038/s41597-024-03635-z | Yes | Yes | Yes | Yes | A.yunnanensis.gff3.gz | A.yunnanensis.pep.fasta.gz | https://figshare.com/articles/dataset/The_genome_annotation_file_of_i_Aquilaria_yunnanensis_i_/24031866/4 |
| Stellera chamaejasme | Hu et al. 2022 | 10.1111/mec.16622 | Yes | Yes | Yes | Yes | langdu.chr.rename.gff.gz | langdu.pep.fa.gz | https://github.com/hhy18/Annotation-files-of-Stellera-chamaejasme |
| Arabidopsis thaliana | Araport11 | 10.1111/tpj.13415 | Yes | Yes | Yes | No | Araport11_GFF3_genes_transposons.current.gff.gz | Araport11_pep_20250411_representative_gene_model.gz | https://www.arabidopsis.org/download/list?dir=Proteins%2FAraport11_protein_lists |
| Theobroma cacao | Cocoa Criollo B97-61/B2 version 2 | 10.1186/s12864-017-4120-9 | Yes | Yes | No | No | Theobroma_cacaoV2_annot_annoted_clean.gff3.tar.gz | Theobroma_cacaoV2_annot_protein.faa.tar.gz | https://cocoa-genome-hub.southgreen.fr/download |
| Gossypium hirsutum | GCF_007990345.1 | 10.1038/s41588-020-0614-5 | Yes | Yes | No | No | genomic.gff | protein.faa | Downloaded from NCBI using their tool as follows: datasets download genome accession PRJNA515894 –filename PRJNA515894-protein-gff3.zip –include protein,gff3 |
The Aquilaria and Stellera species are Thymelaeaceae. The remaining annotations were used in annotating the A. yunnanensis genome.
OMArk
OMArk (v0.3.1, Nevers et al., 2024) was run using the LUCA database as recommended by the OMArk documentation. It was run as follows:
omamer search --db $LUCA --query $query --out results/${query_name}.omamer
omark -f results/${query_name}.omamer -d $LUCA --og_fasta $query --taxid $taxids -o results/${query_name}
This was done for Aquilaria sinensis, Stellera chamaejasme, A. yunnanensis, and Arabidopsis thaliana. For each species, the protein fasta file from the above table above was used as is.
Mono:multi-exonic genes
was used to calculate the proportion of mono-exonic to multi-exonic genes.
Orthofinder
OrthoFinder (v3.1.0, Emms et al., 2025) was run on proteins from Arabidopsis, Stellera, A. sinensis, A. yunnanensis, cotton, and cacao, i.e., the species used for the annotation of A. yunnanensis. The protein fastas used are listed in the table above. For Arabidopsis, A. sinensis, and A. yunnanensis the files were used as-is. For cotton and cacao the OrthoFinder primary_transcripts.py script was used with minor modifications. For cacao, primary_transcripts.py was invoked as:
python primary_transcript.py Theobroma_cacaoV2_annot_protein.faa last_dot_after_space
For Stellera dots were replaced with asterisks as follows:
cat langdu.pep.fa|sed '/>/!s/\./*/g' > langdu.pep.no-dot.fa
OrthoFinder was run without additional parameters.
Expression of A. sinensis in orthogroups
A. sinensis expression analysis
This was a quick-and-dirty analysis of expression in A. sinensis, a side-thing that I had done for some other purpose. It was generated as follows using Nextflow (v24.04.4, Di Tommaso et al., 2017) and the nf-core/rnaseq workflow (v3.18.0, Patel et al., 2024):
nextflow run \
nf-core/rnaseq \
-r 3.18.0 \
--input ${samples_csv} \
--outdir $outdir \
--gtf ${clean_gtf} \
--fasta ${genome_fasta} \
--stringtie_ignore_gtf
The genome used was the A. sinensis chr_genome_assembly.fasta accessible through the link in the table above. were A. sinensis illumina transcriptomics samples available at ENA (European Nucleotide Archive) on 2025-02-12. As
coding_gene.annotation.gff has some issues (e.g., transcripts split across different chromosomes) and was not in line with what the nf-core/rnaseq pipeline required, it had to be cleaned up. The cleaned GTF file was generated as follows:
cat coding_gene.annotation.gff \
| sed 's/\tCDS\t/\texon\t/' \
> coding_gene.annotation.exons.gff
gffread -E coding_gene.annotation.exons.gff -T -o coding_gene.annotation.exons.gtf
cat coding_gene.annotation.exons.gtf \
|sed 's+\(transcript_id \)\([^;]*\);$+gene_id \2; \1\2;+' \
> coding_gene.annotation.exons.gene_ids.gtf
cat coding_gene.annotation.exons.gene_ids.gtf \
| grep -v '"evm.model.Scaffold103.22"' \
| grep -v '"evm.model.Scaffold11.131"' \
| grep -v '"evm.model.Scaffold149.17"' \
| grep -v '"evm.model.Scaffold205.2"' \
| grep -v '"evm.model.Scaffold45.122"' \
| grep -v '"evm.model.Scaffold49.5"' \
| grep -v '"evm.model.Scaffold70.88"' \
| grep -v '"evm.model.Scaffold95.19"' \
> coding_gene.annotation.clean.gtf
Expression in orthogroups
was used to identify the proportion of proteins for each species that are assigned to an orthogroup containing an A. sinensis protein with transcript evidence.
Results
Identified annotations
Among the Thymelaeaceae I have found published annotations for Aquilaria sinensis (Ding et al., 2020), Stellera chamaejasme (Hu et al., 2022), and Aquilaria yunnanensis (Li et al., 2024). There are additional publications on Thymelaeaceae that do annotations, but these do not seem to be publicly available (Chen et al., 2014; Nong et al., 2020; Das et al., 2021).
Overview of the annotations and their issues
The following provides a brief summary of the published annotations, something about how they are generated and some of the issues I’ve identified.
A. sinensis (Ding et al. 2020 doi:10.1093/gigascience/giaa013)
This annotation is built RNA-seq and IsoSeq data, and combines this with homology information and ab initio predictions. Genome versions are provided for the genomes used in the homology analyses, but annotation versions are lacking. There is no information given on which EVM weights are used. A significant issue with this annotation is that the gff file cannot be used as is, as some gene models are split in nonsensical ways across chromosomes. A potential explanation for this is that genome annotation was performed prior to scaffolding, and then transferred.
Stellera chamaejasme (Hu et al. 2022 doi:10.1111/mec.16622)
This annotation combines homology data with ab initio predictions. Ab initio predictions were based on Arabidopsis parameters for two out of three methods. This annotation is not built on any transcript data. The publication itself does not specify which exact annotation versions were used from other species, though the author has clarified this in the GitHub repo.
The major issue with this annotation is the lack of transcript evidence, combined with EVidenceModeler being used to combine homology and ab initio predictions with equal weights. Using EVM in this way means that it is possible that ab initio predictions overrule homology evidence.
A. yunnanensis (Li et al. 2024 doi:10.1038/s41597-024-03635-z)
This annotation combines IsoSeq data with homology information and ab initio predictions. For some species it is not clear which exact annotations were used as inputs as annotation versions are not given. A minor issue is that the gff file and the genome fasta file have different identifiers for the chromosomes.
OMArk
The following figures show the OMArk result for A. sinensis, Stellera, A. yunnanensis and Arabidopsis.
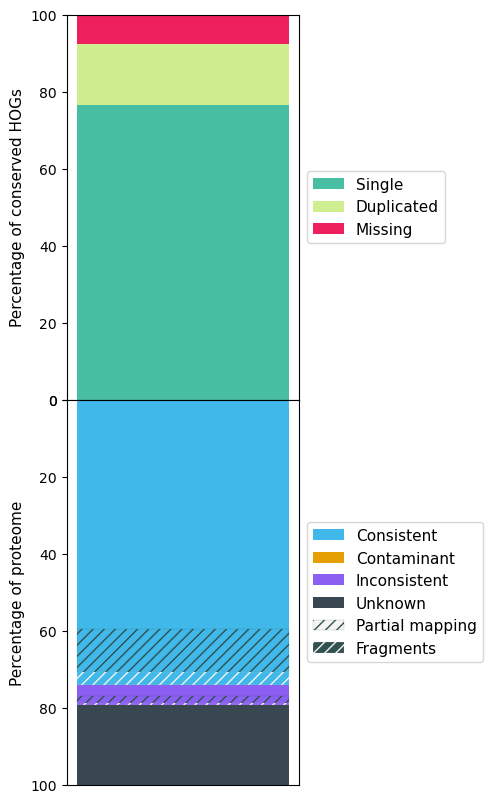 A. sinensis OMArk results
A. sinensis OMArk results
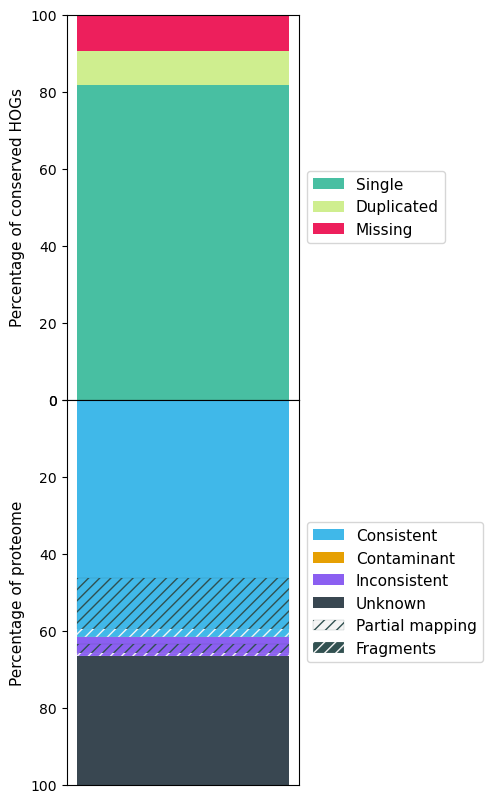 Stellera OMArk results
Stellera OMArk results
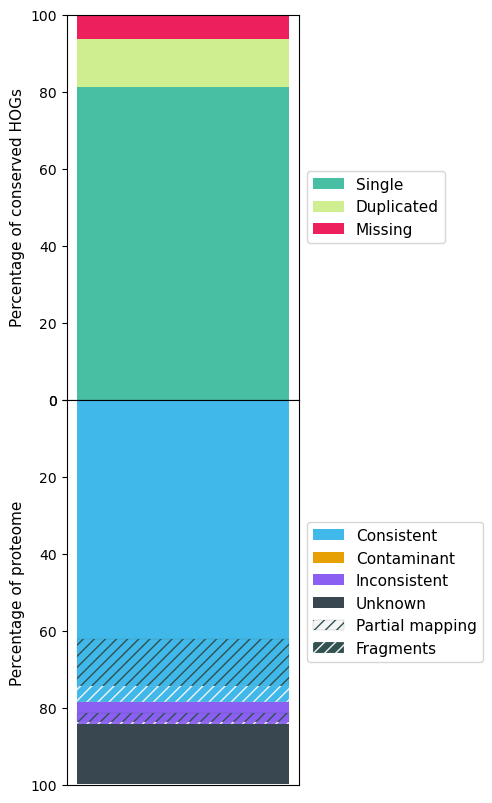 A. yunnanensis OMArk results
A. yunnanensis OMArk results
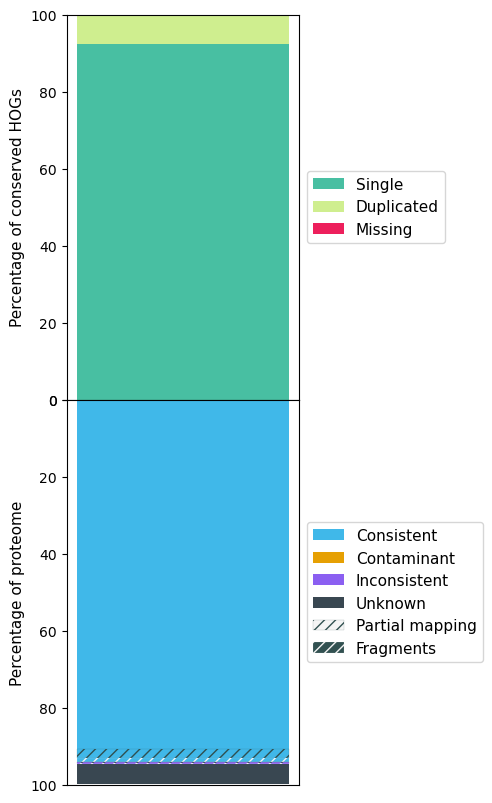 Arabidopsis OMArk results
Arabidopsis OMArk results
The following tables provide more detailed results:
Clade used by OMArk
| A. sinensis | Stellera | A. yunnanensis | Arabidopsis | |
|---|---|---|---|---|
| Clade used | malvids | malvids | malvids | Brassicaceae |
| Number of conserved HOGs in clade | 11704 | 11704 | 11704 | 17996 |
Results on conserved HOGs
| A. sinensis | Stellera | A. yunnanensis | Arabidopsis | |
|---|---|---|---|---|
| Single | 8959 (76.55%) | 9550 (81.60%) | 9515 (81.30%) | 16601 (92.25%) |
| Duplicated | 1836 (15.69%) | 1034 (8.83%) | 1441 (12.31%) | 1313 (7.30%) |
| Duplicated, Unexpected | 1825 (15.59%) | 1027 (8.77%) | 1428 (12.20%) | 236 (1.31%) |
| Duplicated, Expected | 11 (0.09%) | 7 (0.06%) | 13 (0.11%) | 1077 (5.98%) |
| Missing | 909 (7.77%) | 1120 (9.57%) | 748 (6.39%) | 82 (0.46%) |
OMArk consistensy assessment
| A. sinensis | Stellera | A. yunnanensis | Arabidopsis | |
|---|---|---|---|---|
| Number of proteins in the whole proteome | 29203 | 30933 | 27955 | 27644 |
| A. sinensis | Stellera | A. yunnanensis | Arabidopsis | |
|---|---|---|---|---|
| Total Consistent | 21686 (74.26%) | 19090 (61.71%) | 21966 (78.58%) | 26002 (94.06%) |
| Consistent, partial hits | 3301 (11.30%) | 4069 (13.15%) | 3419 (12.23%) | 685 (2.48%) |
| Consistent, fragmented | 984 (3.37%) | 677 (2.19%) | 1182 (4.23%) | 228 (0.82%) |
| Total Inconsistent | 1513 (5.18%) | 1497 (4.84%) | 1619 (5.79%) | 155 (0.56%) |
| Inconsistent, partial hits | 550 (1.88%) | 745 (2.41%) | 598 (2.14%) | 79 (0.29%) |
| Inconsistent, fragmented | 170 (0.58%) | 182 (0.59%) | 202 (0.72%) | 38 (0.14%) |
| Total Contaminants | 0 (0.00%) | 0 (0.00%) | 0 (0.00%) | 0 (0.00%) |
| Contaminants, partial hits | 0 (0.00%) | 0 (0.00%) | 0 (0.00%) | 0 (0.00%) |
| Contaminants, fragmented | 0 (0.00%) | 0 (0.00%) | 0 (0.00%) | 0 (0.00%) |
| Total Unknown | 6004 (20.56%) | 10346 (33.45%) | 4370 (15.63%) | 1487 (5.38%) |
Mono:multi-exonic genes
The following table shows the number of mono- and multi-exonic protein coding genes per species, as well as the ratio between them.
| Species | Mono-exonic | Multi-exonic | Total genes | Mono:multi-ratio |
|---|---|---|---|---|
| A. sinensis | 6815 | 22388 | 29203 | 0.304404 |
| Stellera | 9138 | 21795 | 30933 | 0.41927 |
| A. yunnanensis | 7710 | 20245 | 27955 | 0.380835 |
| Arabidopsis | 5272 | 22261 | 27533 | 0.236827 |
Orthofinder
OrthoFinder generates a total of 38,717 orthogroups, with 16,219 of these containing only a single protein. The distribution of the numbers of proteins per orthogroup looks as follows:
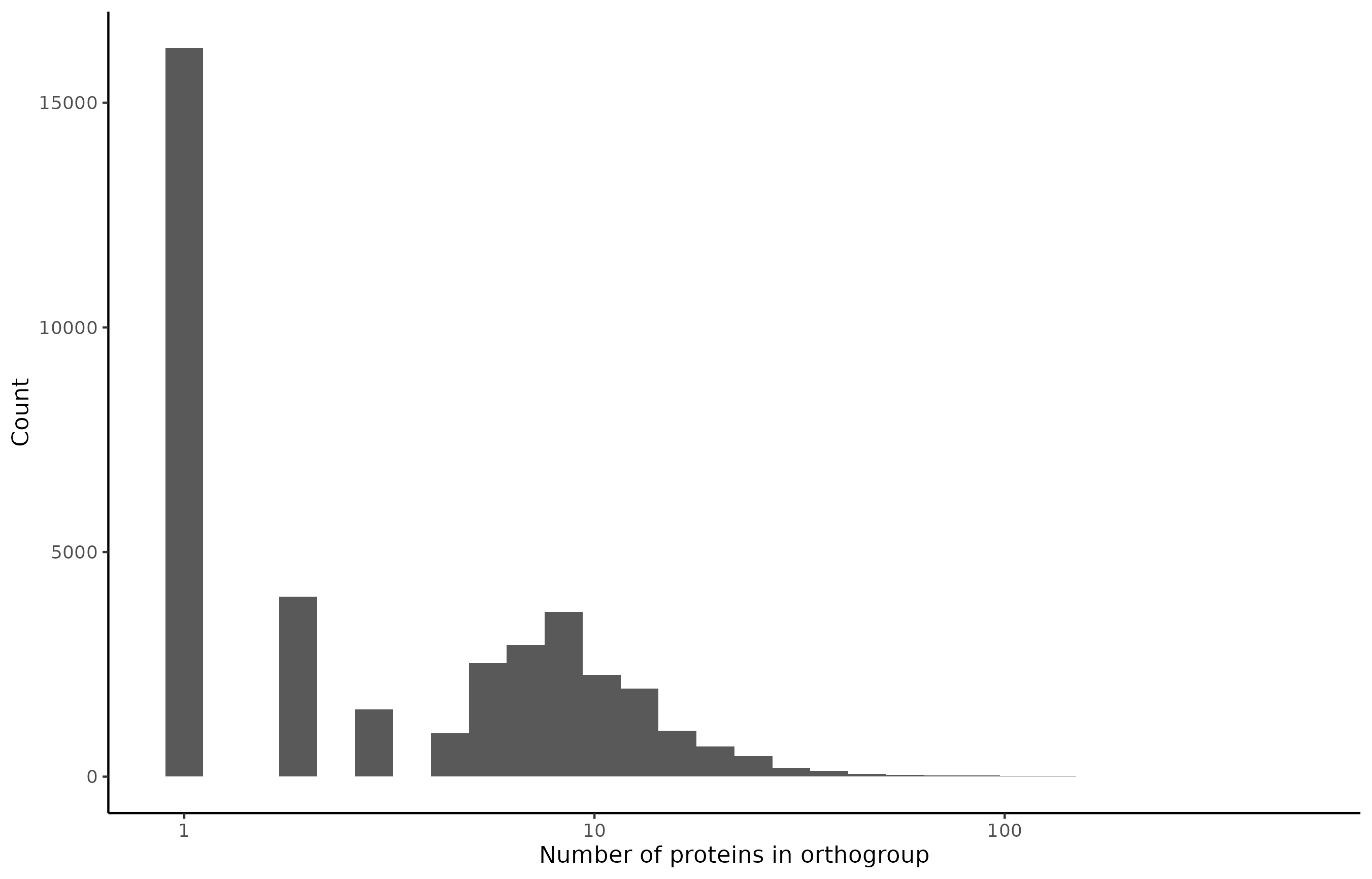
For each species, the number of proteins, and whether the protein belongs to a single-protein or multi-protein orthogroup is illustrated below:
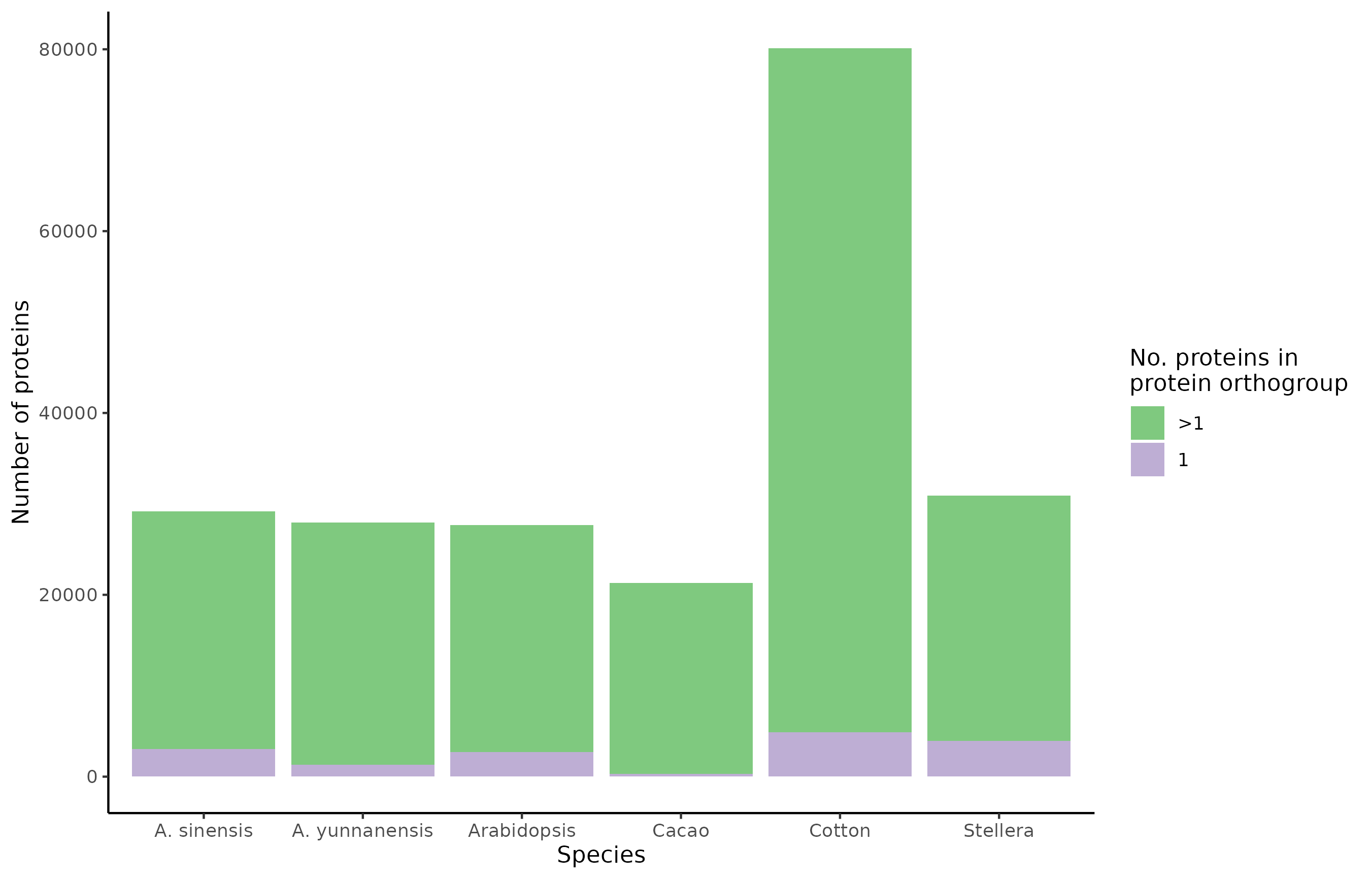
Among the orthogroups, the species co-occur as follows:
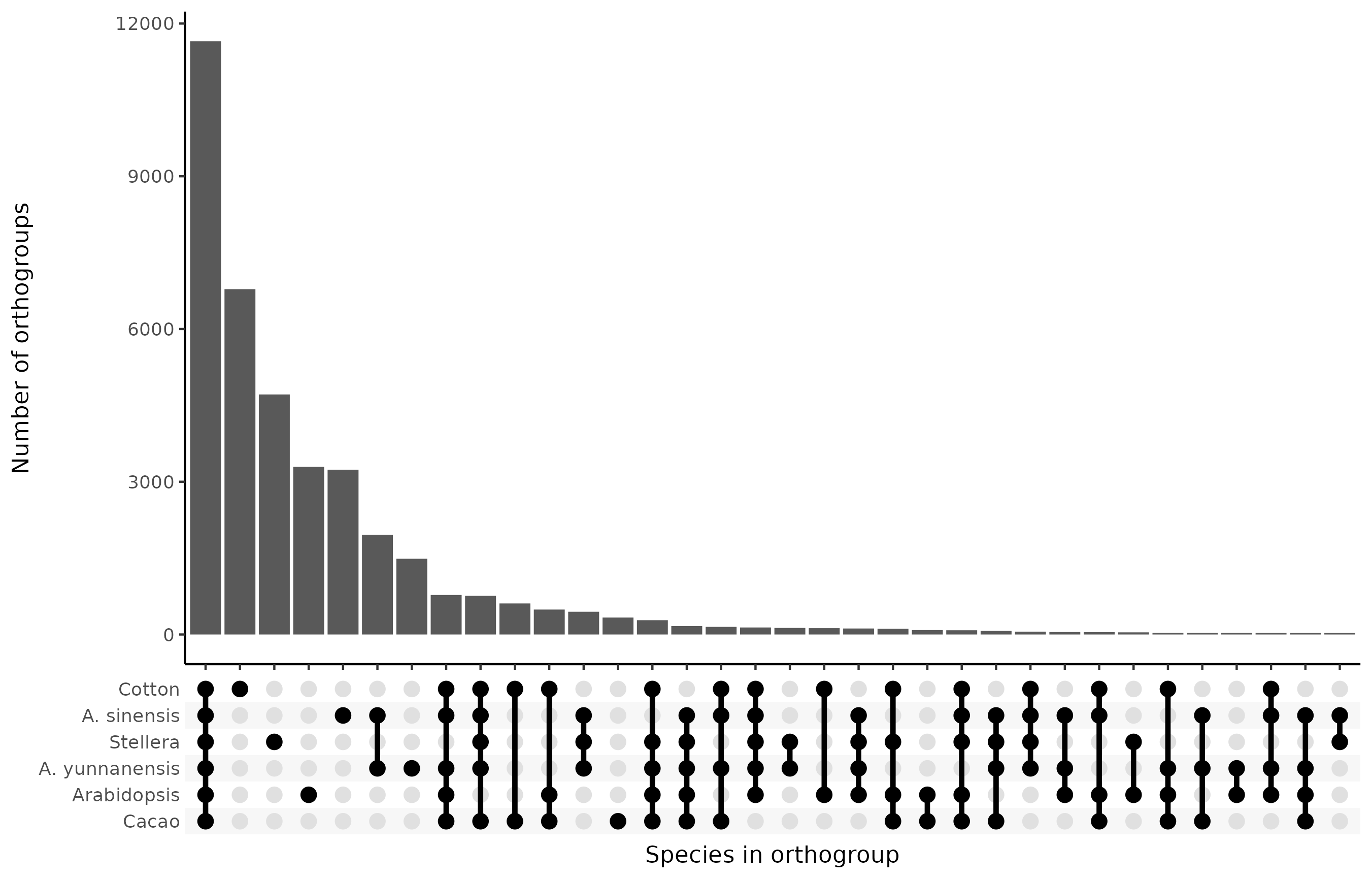
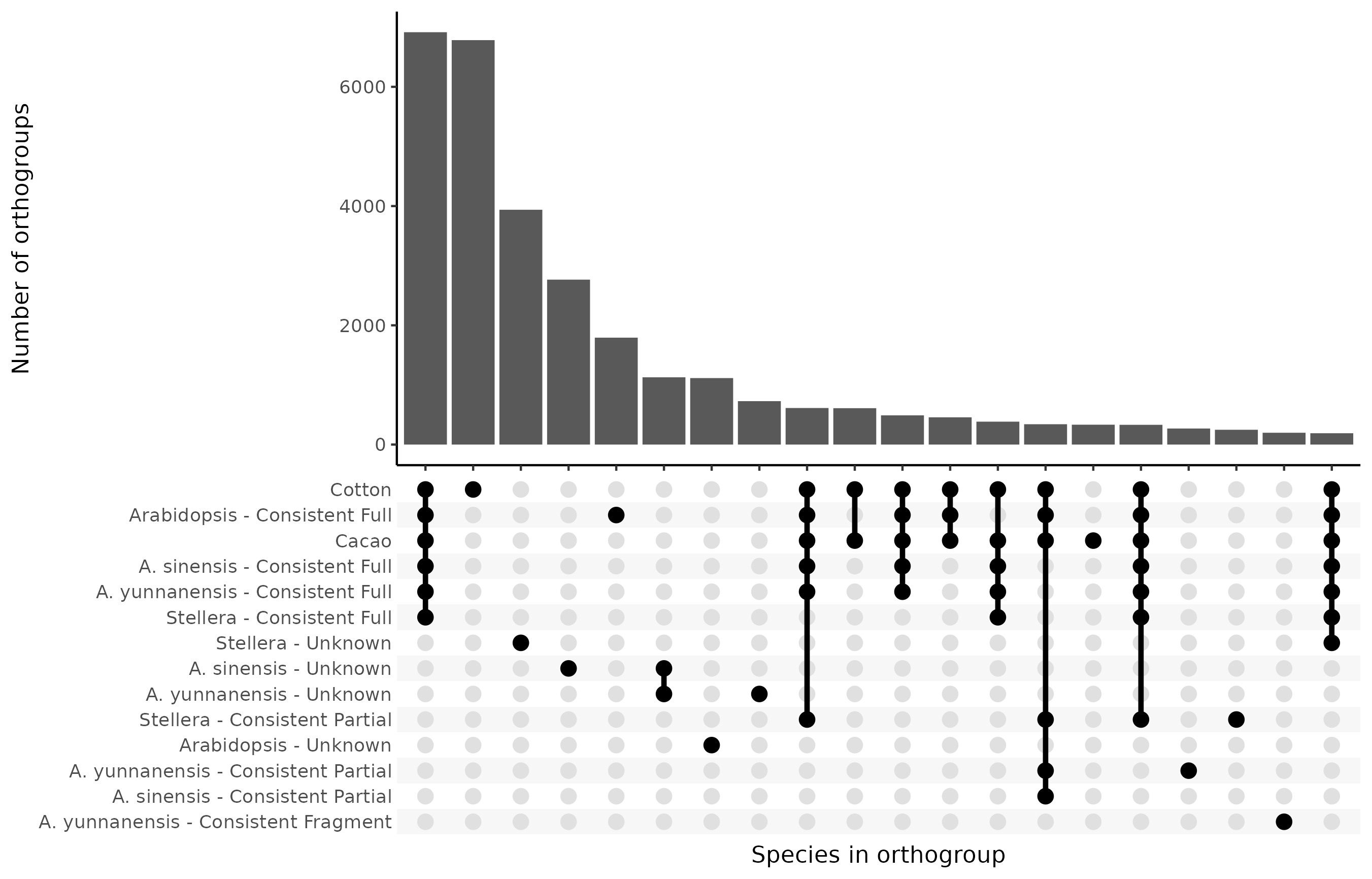
Adding in the OMArk categories for the species analyzed using that tool to the above, the distribution looks as follows:
A. sinensis expression analysis
The following table shows the number of proteins per species that belong to an orthogroup containing a protein with RNA-seq evidence from A. sinensis.
| Species | Not expressed | Expressed | Total | Expressed out of total |
|---|---|---|---|---|
| A. sinensis | 2475 | 26728 | 29203 | 0.9152484 |
| Stellera | 9172 | 21761 | 30933 | 0.7034882 |
| A. yunnanensis | 3206 | 24749 | 27955 | 0.8853157 |
| Arabidopsis | 8139 | 19511 | 27650 | 0.7056420 |
| Cacao | 2861 | 18469 | 21330 | 0.8658697 |
| Cotton | 21511 | 58628 | 80139 | 0.7315789 |
Discussion
The above analysis attempts to provide an overview of the state of Thymelaeaceae annotations. In short, all the published annotations have various problems, but both the Aquilaria annotations are based in part on transcriptome data, and it it clear that a large proportion of the published proteins, including a number of those that OMArk classifies as Unknown, are plausibly expressed.
Among the published annotations I am most skeptical of the Stellera annotation. It is not based on any Stellera transcript data, and I think that the way it uses EVM to combine evidence is bad. The authors themselves acknowledge that 28% of their predicted genes do not match anything present in the databases they check against. It has a high proportion of OMArk Unknowns and a high proportion of mono-exonic genes. More than a thousand orthogroups contain proteins from both the Aquilaria species, where all proteins are also classified as Unknown by OMArk, while close to four thousand orthogroups contain only Unknown Stellera proteins. This means that it is unclear whether these Stellera proteins being classified as Unknowns is a result of the proteins not being real, or is caused by a lack of coverage in the database used by OMArk.
The methods I’m using here come with very clear limitations. The small number of Thymelaeaceae annotations means that e.g. the OMArk database has gaps for these species, which means that the results reflect both the quality of the annotations, but to some extent also the quality of the database. As my focus has been on the Thymelaeaceae, there may be nuances in the cacao, cotton or Arabidopsis annotations that could potentially shift some results slightly.
As I point out in the methods, counting proteins present in orthogroups where A. sinensis has a protein backed by transcript evidence is a very hacky solution born out of convenience. Those results does say something about the Aquilarias and cacoa, i.e., that a large proportion of their proteins end up in similar orthogroups and that these orthogroup contains A. sinensis proteins with transcript evidence. What we can say is that the Stellera’s OMArk Unknowns can’t be easily explained as only a result of bad database coverage – this is yet another thing pointing to a lot of these proteins potentially being artifacts.
References
Argout, X. et al. (2017) ‘The cacao Criollo genome v2.0: an improved version of the genome for genetic and functional genomic studies’, BMC Genomics, 18(1), pp. 1–9. Available at: https://doi.org/10.1186/s12864-017-4120-9.
Chen, C.-H. et al. (2014) ‘Identification of cucurbitacins and assembly of a draft genome for Aquilaria agallocha’, BMC genomics, 15(1), p. 578. Available at: https://doi.org/10.1186/1471-2164-15-578.
Chen, Z.J. et al. (2020) ‘Genomic diversifications of five Gossypium allopolyploid species and their impact on cotton improvement’, Nature Genetics, 52(5), pp. 525–533. Available at: https://doi.org/10.1038/s41588-020-0614-5.
Cheng, C.-Y. et al. (2017) ‘Araport11: a complete reannotation of the Arabidopsis thaliana reference genome’, The Plant Journal, 89(4), pp. 789–804. Available at: https://doi.org/10.1111/tpj.13415.
Das, A. et al. (2021) ‘Genome-wide detection and classification of terpene synthase genes in Aquilaria agallochum’, Physiology and Molecular Biology of Plants, 27(8), pp. 1711–1729. Available at: https://doi.org/10.1007/s12298-021-01040-z.
Di Tommaso, P. et al. (2017) ‘Nextflow enables reproducible computational workflows’, Nature Biotechnology, 35(4), pp. 316–319. Available at: https://doi.org/10.1038/nbt.3820.
Ding, X. et al. (2020) ‘Genome sequence of the agarwood tree Aquilaria sinensis (Lour.) Spreng: the first chromosome-level draft genome in the Thymelaeceae family’, GigaScience, 9(3), p. giaa013. Available at: https://doi.org/10.1093/gigascience/giaa013.
Emms, D.M. et al. (2025) ‘OrthoFinder: scalable phylogenetic orthology inference for comparative genomics’. Available at: https://doi.org/10.1101/2025.07.15.664860.
Hu, H. et al. (2022) ‘Genomic divergence of Stellera chamaejasme through local selection across the Qinghai–Tibet plateau and northern China’, Molecular Ecology, 31(18), pp. 4782–4796. Available at: https://doi.org/10.1111/mec.16622.
Jain, M. et al. (2008) ‘Genome-wide analysis of intronless genes in rice and Arabidopsis’, Functional & Integrative Genomics, 8(1), pp. 69–78. Available at: https://doi.org/10.1007/s10142-007-0052-9.
Li, M. et al. (2024) ‘Chromosome-level genome assembly of Aquilaria yunnanensis’, Scientific Data, 11(1), p. 790. Available at: https://doi.org/10.1038/s41597-024-03635-z.
Nevers, Y. et al. (2024) ‘Quality assessment of gene repertoire annotations with OMArk’, Nature Biotechnology, pp. 1–10. Available at: https://doi.org/10.1038/s41587-024-02147-w.
Nong, W. et al. (2020) ‘Chromosomal-level reference genome of the incense tree Aquilaria sinensis’, Molecular Ecology Resources, 20(4), pp. 971–979. Available at: https://doi.org/10.1111/1755-0998.13154.
Patel et al. (2024) ‘nf-core/rnaseq: nf-core/rnaseq v3.18.0 - Lithium Lynx’. Zenodo. Available at: https://doi.org/10.5281/ZENODO.14537300.
Pertea, G. and Pertea, M. (2020) ‘GFF Utilities: GffRead and GffCompare’, F1000Research, 9, p. 304. Available at: https://doi.org/10.12688/f1000research.23297.1.
Vuruputoor, V.S. et al. (2023) ‘Welcome to the big leaves: Best practices for improving genome annotation in non-model plant genomes’, Applications in Plant Sciences, 11(4), p. e11533. Available at: https://doi.org/10.1002/aps3.11533.
Image attributions
The following images have been used for the poster:
- Photo of A. malaccensis by Muhd Amirul Rasdey Abdullah, CC BY-SA 4.0
- Photo of A. sinensis by Chong Fat, CC BY-SA 3.0
- Photos of Stellera chamaejasme by Urgamal Magsar, CC BY 4.0
- Photos of Wikstroemia by Ruben Cousins Westerberg
{kind=link}
{kind=link}